Supervised Learning + Reinforcement Learning
Training and Deploying Neural Connect 4 Agents
A two-phase ML project: first training CNN and Transformer networks on MCTS self-play data (81.7% Top-1 accuracy), then extending into reinforcement learning with Policy Gradient, DQN, and SAC agents — with a DQN reaching 76.2% win rate and the team advancing to the class tournament championship.
- Phase 1 — Supervised
- Game AI, MCTS supervision, CNN/Transformer architecture comparison, cloud deployment
- Phase 2 — Reinforcement Learning
- Policy Gradient, Dueling Double DQN, Soft Actor-Critic, curriculum self-play
- Training Stack
- Python, TensorFlow/Keras, NumPy, MCTS, Google Colab
- Deployment
- AWS Lightsail, Docker, Anvil (Python web app)
System Architecture
This project was architected as a production-style ML pipeline rather than a standalone notebook. Clear separation of responsibilities mirrors real-world deployment patterns.
MCTS Self-Play → Dataset Generation → Model Training (Colab GPU) → Model Serialization (.h5) → Dockerized Inference API (AWS Lightsail) → Anvil Frontend (Authenticated UI) → Human vs Bot Gameplay
| Layer | Responsibility |
|---|---|
| Training | Model development and experimentation |
| AWS Backend | Stateless inference only |
| Docker | Environment reproducibility |
| Anvil Frontend | Authentication, UI, state management |
Data Generation
Rather than hand-labeling positions, MCTS was used as a high-quality move generator. The pipeline ran 1,500 self-play games with 1,200 rollouts per move over ~15 hours. Randomized early moves increased diversity; duplicate board states were consolidated via majority vote.
Model Results
| Metric | CNN | Hybrid Transformer |
|---|---|---|
| Top-1 Accuracy | 78.3% | 81.7% |
| Top-2 Accuracy | 92.4% | 94.1% |
| Inference Time | 1.2 ms | 3.8 ms |
| Training Time | ~20 min | ~2 hours |
| Best Use Case | Real-time, lightweight deployment | Maximum move prediction accuracy |
The hybrid model improves top-1 accuracy by 3.4 points. The CNN trades a small accuracy drop for 3x faster inference and 6x faster training, making it ideal for real-time deployment.
Architecture Journey
CNN: Iterative Refinement
Initial models exposed classic failure modes: shallow CNN underfit (~60%), deep CNN overfit, heavy regularization caused capacity collapse. The final CNN balanced depth and generalization with progressive convolution blocks (32 → 256 filters), batch normalization, dropout scheduling, and Global Average Pooling.
Pure Transformer
Performance plateaued at 46–55% accuracy. The 6×7 board is too small for effective token diversity, and transformers lack inductive spatial bias. Conclusion: transformers without feature extraction underperform on compact spatial domains.
Hybrid CNN–Transformer
CNN feature extractor compresses to 3×3 spatial tokens, then a 4-layer Transformer encoder and dense classification head. This combined spatial priors with global attention for the best overall accuracy.
Tactical Error Analysis
High Confidence (>95%)
- •Immediate wins: 98%+ accuracy
- •Forced defensive blocks
- •Opening central control
Failure Modes (<65%)
- •Multi-move traps
- •Dense endgames
- •Zugzwang states
Neural networks approximate pattern recognition but cannot simulate future branches. This reflects the historical evolution from supervised AlphaGo to AlphaZero-style policy + search hybrids.
Deployment
AWS Lightsail Backend
- •Dockerized TensorFlow inference service
- •Model loaded at startup, stateless requests
- •Returns probability distribution over 7 moves
- •Deterministic, low-latency inference (<4 ms)
Anvil Frontend
- •Authenticated UI (email/password, no auto signup)
- •Model selector (CNN vs Transformer)
- •Real-time human vs bot gameplay
- •Tab navigation: Play Game | Training Description
Anvil UI
The frontend was designed to resemble a polished consumer product: gradient background, rounded board container, elevated shadows, distinct yellow/red piece styling, animated feedback messages.
Game interface with model selector and board

Interactive gameplay view
Model Performance Visualization
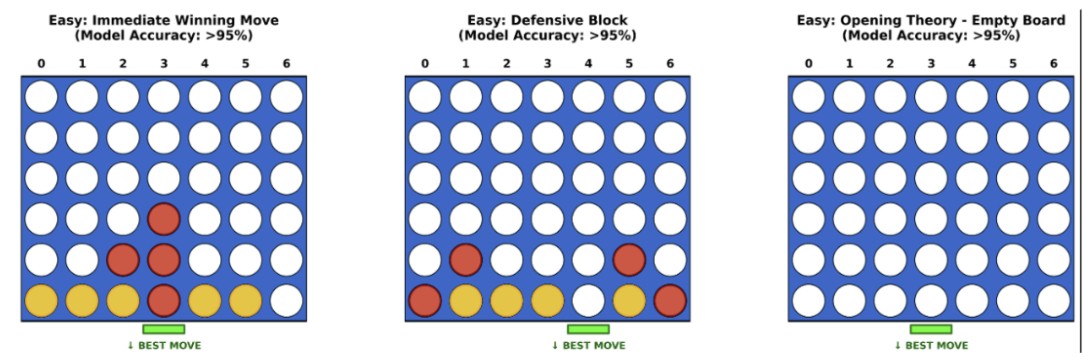
High-confidence board states where models excel

Challenging scenarios (multi-move traps, endgames)
Engineering Tradeoffs
| Dimension | CNN | Hybrid Transformer |
|---|---|---|
| Accuracy | Strong | Best |
| Latency | Excellent | Moderate |
| Training Cost | Low | High |
| Implementation Complexity | Moderate | High |
Both models were deployed to allow direct comparison in the live Anvil app.
Key Takeaways
- • Inductive bias matters more than model novelty; small spatial grids favor CNNs
- • Transformers benefit from hybridization with spatial feature extractors
- • Supervised imitation from MCTS labels has inherent planning limits; neural-guided search (AlphaZero-style) is the natural next step
- • Production deployment adds non-trivial engineering overhead: containerization, cloud hosting, authenticated UI
Phase 2: Reinforcement Learning Extension
The supervised models served as the starting point for a full reinforcement learning project (Optimization II, UT Austin MSBA). Starting from six supervised networks as baselines, we implemented and compared three RL paradigms through self-play against a growing opponent pool.
Each agent was trained via self-play against a pool seeded with the supervised baselines plus frozen snapshots of the improving agent — ensuring the opponent grew stronger alongside the learner.
Policy Gradient
Directly optimized a column-distribution policy network using discounted-return-weighted log-probability gradients (REINFORCE). Trained over 500 groups of 20 games each, with stochastic move sampling for exploration and an entropy coefficient of 0.03 to balance sharpening vs. exploration.
Dueling Double DQN (v4)
Learned a state-action value function Q(s,a) with a pre-allocated circular replay buffer, target-network synchronisation, and curriculum self-play (20–50% self-play fraction). DQN v4 resumed from v3 weights with curriculum self-play added, recovering the vs-random win rate that had degraded in v3 while improving overall average.
Soft Actor-Critic + MCTS Tournament Submission
Fused actor-critic learning with Monte Carlo Tree Search at inference time. The SAC policy network guided MCTS rollouts, combining learned value estimates with tree search lookahead — the same paradigm as AlphaZero. Trained over ~820 groups of 128 games each with 16 gradient updates per group, then paired with MCTS for the final tournament.
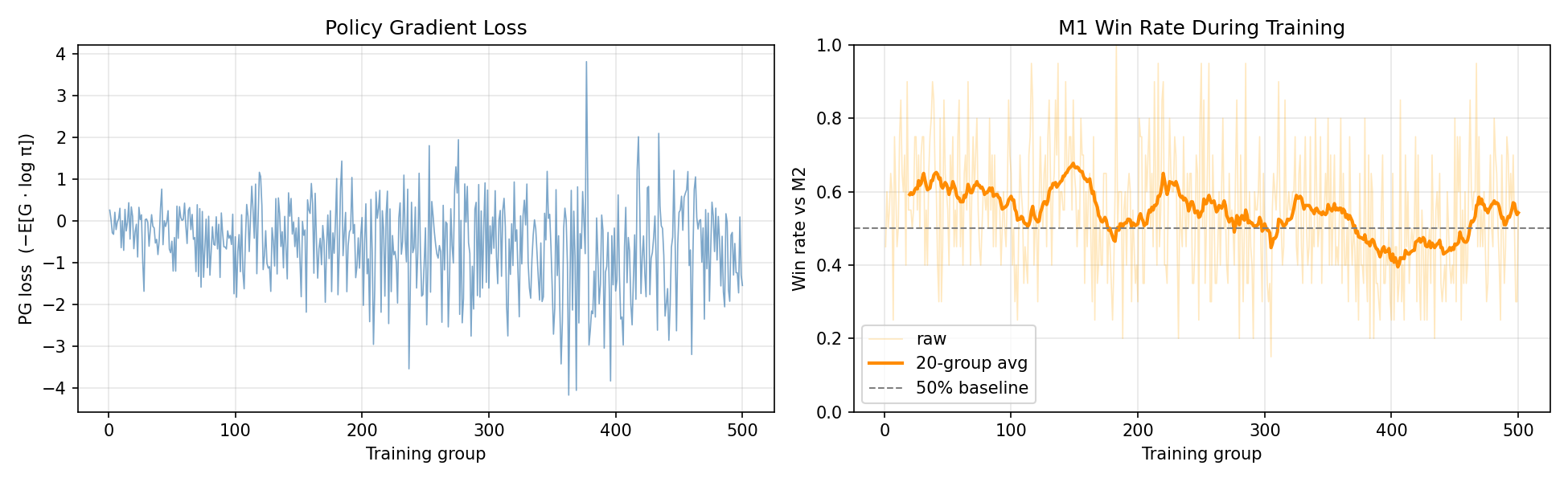
Policy Gradient — loss and win rate over 500 training groups
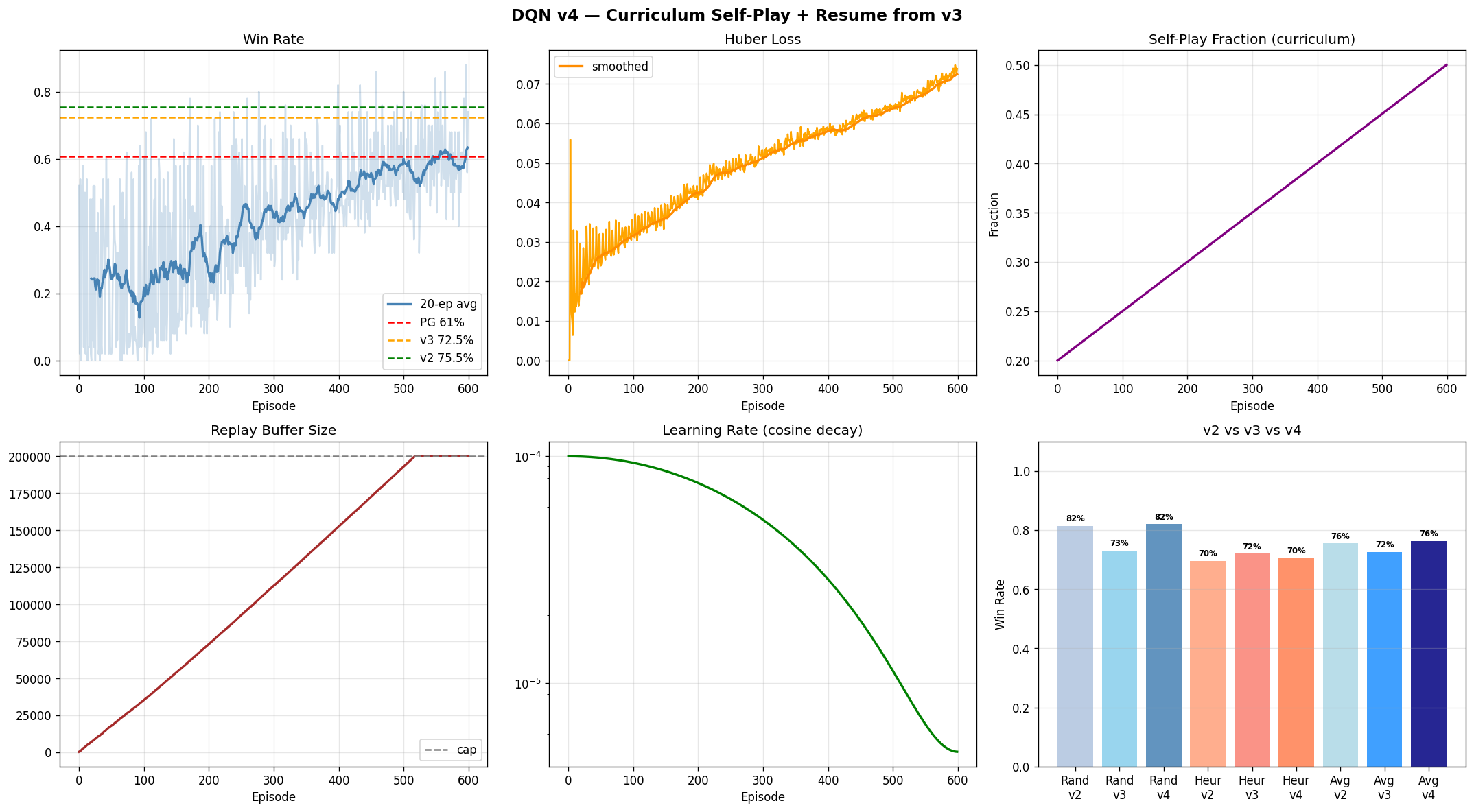
DQN v4 — episode win rate, Huber loss, and curriculum self-play fraction
Agent Comparison
| Agent | vs. Random | vs. 1-ply | Mean |
|---|---|---|---|
| Policy Gradient | — | — | 60.8% |
| DQN v2 | 81.5% | 69.5% | 75.5% |
| DQN v3 | 73.0% | 72.0% | 72.5% |
| DQN v4 | 82.0% | 70.5% | 76.2% |
| SAC + MCTS ★ Tournament | 81.5% | 69.5% | 75.5% + search |
Class Tournament
Advanced to the Championship
The SAC agent paired with MCTS at inference was submitted to the end-of-semester class tournament against all other groups' trained agents. The team advanced to the championship round — the strongest result in the class.
Outcome
Across both phases, this project spans MCTS-supervised training, architecture experimentation, cloud deployment, and full reinforcement learning — from policy gradient through DQN curriculum self-play to Soft Actor-Critic. The supervised phase achieved 81.7% Top-1 move accuracy with sub-4ms inference. The RL phase culminated in a SAC agent paired with MCTS at inference — combining learned value estimates with tree-search lookahead — which advanced to the class tournament championship.